Análisis Léxico¶

Para esta asignación, van a escribir un analizador léxico, también llamado lexer, utilizando un generador de analizadores léxicos llamado JLex. Ustedes van a describir el set de tokens para COOL en un formato adecuado y JLex va a generar el código de Java para reconocer tokens en programas escritos en COOL.
La documentación para las herramientas está abajo en la sección de Referencias.
1. Introducción a JLex¶
JLex permite implementar un analizador léxico escribiendo expresiones regulares y establecer acciones cuando alguna secuencia de caracteres hace match con alguna de estas. JLex convierte estas reglas que ustedes van a definir en un archivo llamado lexer.lex en un archivo de Java con el código que implementa un autómata finito que puede reconocer estas expresiones regulares que ustedes especificaron en el archivo lexer.lex. Afortunadamente, no es necesario entender o incluso mirar lo que automáticamente genera JLex. Los archivos que entiende JLex estan estructurados de la siguiente manera:
%{
Declaraciones
%}
Definiciones
%%
Reglas
%%
Subrutinas de Usuario
Las secciones de Declaraciones y Subrutinas de Usuario son opcionales y les permite a ustedes escribir declaraciones y funciones de ayuda en Java. Las sección de Definiciones también es opcional, pero en general es bastante útil porque las definiciones les permiten a ustedes darle nombres a las expresiones regulares. Por ejemplo, la siguiente definición:
DIGIT = [0-9]
Les permite definir un dígito. Aquí, DIGIT es el nombre que se le da a la expresión regular que hace match con cualquier caracter que esté entre 0 y 9. La siguiente tabla les da una vista general de expresiones regulares comunes que pueden ser especificadas en JLex.
| Expresión | Descripción |
|---|---|
| x | el caracter x |
| "x" | caracter x, incluso si x es un operador |
| \x | caracter x, incluso si x es un operador |
| [xy] | el caracter x o y |
| [x-z] | los caracteres x, y, z |
| [^x] | cualquier caracter excepto x |
| . | cualquier caracter excepto newline |
| ^x | caracter x al inicio de una linea |
| <y>x | caracter x cuando JLex esta en el estado <y> |
| x$ | caracter x al final de una linea |
| x? | el caracter x es opcional |
| x* | el caracter x aparece 0 o más veces |
| x+ | el caracter x aparece 1 o más veces |
| x|y | caracter x o y |
| (x) | caracter x |
| x/y | caracter x si y solo si es seguido de un caracter y |
| {xx} | hace referencia a la definición xx |
| x{m,n} | caracter x aparece entre m y n veces |
La parte más importante de su analizador léxico es la sección de reglas. Una regla en JLex especifica una acción a tomar si la entrada hace match con la expresión regular o definición al principio de la regla. La acción a tomar es especificada escribiendo código de Java regular. Por ejemplo, asumiendo que un dígito representa un token en nuestro lenguaje (noten que este no es el caso de COOL), la regla sería entonces:
{DIGIT} { AbstractSymbol num = AbstractTable.inttable.addString(yytext()); return new Symbol(TokenConstants.INT_CONST, num); }
Esta regla guarda el valor del dígito en una variable global AbstractTable.inttable y retorna el código apropiado para el token.
Java
Vean la sección Notas de Java para una discusión más detallada de la variable global AbstractTable.inttable y vean la sección Tabla de Strings para una discusión sobre como AbstractTable.inttable es utilizado en el código de arriba.
Un punto importante a recordar es que la entrada actual (es decir, el resultado de llamar a la función next_token()) puede hacer match con múltiples reglas, JLex toma la regla que hace match con el mayor número de caracteres. Por ejemplo, si ustedes definieran las siguientes dos reglas:
[0-9]+ { // action 1 } [0-9a-z]+ { // action 2 }
y si la secuencia de caracteres "2a" aparece en el archivo que está siendo analizado, entonces la acción 2 va a tomarse, dado que la segunda regla hace match con más caracteres que la primer regla. Si múltiples reglas hacen match con la misma cantidad de caracteres, entonces la regla que aparece primero es la que se toma.
Cuando escriban reglas en JLex, va a ser necesario que se tomen diferentes acciones dependiendo de los tokens encontrados anteriormente. Por ejemplo, cuando esten procesando un token que representa el cierre de un comentario, a ustedes les va a interesar saber si un token que representa abrir comentario se ha encontrado anteriormente. Usted podría implementar esto con algunas variables globales en la sección de declaraciones y cambiarlas cuando ciertos tokens de interés son encontrados, sin embargo, JLex le facilita esto mediante los estados:
%state COMMENT
Usted puede moverse a este estado escribiendo yybegin(COMMENT). Para tomar una acción si y solo si un token que representa abrir comentario ha sido encontrado anteriormente, usted usaría la siguiente sintaxis:
<COMMENT> reg_exp { // action }
Hay un estado default llamado YINITIAL que está activo al inicio, hasta que ustedes se mueven a otro utilizando yybegin(STATE). Ustedes pueden encontrar útil esta sintaxis para varios aspectos de esta asignación, así como reportar errores. Nosotros les recomendamos que lean detenidamente la documentación de JLex antes de empezar a escribir su analizador léxico.
2. Archivos y Directorios¶
Para este punto ya debe tener instalado el material.
Vaya a su carpeta PA1 y ADENTRO de esta ejecute este comando:
make -f /usr/class/cc4/assignments/PA1/Makefile
Este comando va a copiar un número de archivos en su directorio que han creado. Algunos de los archivos que van a ser copiados van a ser de solo lectura (representando a estos con archivos que realmente son enlaces simbólicos hacia otros archivos). Ustedes no deberían de editar estos archivos. De hecho, si ustedes modifican estos archivos, van a encontrar imposible terminar y completar esta asignación. Vean las instrucciones en el archivo README. Los únicos archivos que tienen permitido modificar para esta asignación son:
- cool.lex: Este archivo contiene un esqueleto para una descripción léxica de COOL. Hay comentarios que indican donde ustedes tienen que llenar con código, pero esto no es necesariamente una guía completa. Una parte de la asignación es que ustedes se aseguren que tienen un analizador léxico funcional. Exceptuando las secciones indicadas, ustedes son libres de hacer modificaciones a todo el archivo. El archivo tal como viene ya permite generar un analizador léxico, pero este no hará casi nada todavía. Cualquier función de ayuda que ustedes deseen escribir tiene que ser añadida directamente a este archivo en la sección apropiada (vean los comentarios en el archivo).
- test.cl: Este archivo contiene un programa de COOL ejemplo para que sea analizado. Este archivo no representa toda la especificación léxica del lenguaje COOL, pero de todas maneras es una prueba interesante. Siéntanse libres de modificar este archivo para probar su analizador léxico.
- README: Este archivo contiene instrucciones detalladas para la asignación, así como también un número de recomendaciones útiles. Realmente este archivo no lo van a modificar, pero es bueno mencionar que lo tienen que leer.
Otros archivos
No modifiquen ningún archivo que no se menciona en el listado, cuando se evalue la asignación únicamente se va a probar el archivo cool.lex en un nuevo entorno.
3. Resultados del Lexer¶
Antes de empezar con esta asignación, estudien los diferentes tokens que están definidos en el archivo TokenConstants.java. En esta asignación, ustedes tiene que escribir reglas de JLex que correspondan con todos los tokens validos en COOL, como se describe en la sección número 10 y figura 1 del manual de COOL. Para cada tipo de token deben tomar las acciones apropiadas, como retornar un Symbol del tipo correcto, guardar el valor del lexema cuando sea necesario, o reportar un error cuando estos se presenten.
Por ejemplo, si ustedes hacen match del token BOOL_CONST, su analizador léxico tiene que guardar el su valor ya sea que sea true o false. Otro ejemplo, si hacen match con el token TYPEID, ustedes van a tener que guardar el nombre del tipo. Noten que no todos los tokens requieren que se guarde información adicional, por ejemplo, es suficiente que solo se devuelva el tipo de token con el que se hizo match cuando se hace match con algún keyword del lenguaje como class.
Su lexer debe de ser robusto, debería de funcionar con cualquier input. Por ejemplo, deberían de manejar errores como cuando se encuentra un caracter de EOF en medio de un string o comentario, error por un string demasiado largo, etc.. Estos son solo algunos de los errores que pueden ser encontrados, lean el manual para conocer el resto. Ustedes tienen que terminar su análisis de forma elegante si algún error fatal ocurre. Las excepciones no manejadas NO son aceptables.
3.1 Manejo de Errores¶
Todos los errores deberían de ser pasados al parser. Su lexer no debería de imprimir NADA. Los errores se comunican al parser retornando un token de error especial llamado ERROR, en mayúscula, junto con el mensaje de error.
error en minúscula
Ignoren el token error en minúscula durante su fase 1, lo utilizamos hasta la fase siguiente. Ignoren también el token LET_STMT.
A continuación información sobre los errores en strings reportar, y su recuperación:
- Cuando un caracter inválido (alguno que no puede ser algún token) se encuentra, un string que contenga solo ese caracter debería de ser retornado como el error. Tienen que continuar el análisis con el siguiente caracter.
- Si un string contiene un newline sin escape (
\\), tienen que reportar el error como "Unterminated string constant" y continuar el análisis léxico al principio de la siguiente línea. Es decir, estamos asumiendo que el usuario simplemente olvido cerrar el string con una comilla. - Cuando un string es demasiado largo, tienen que reportar el error "String constant too long".
- Si el string contiene el caracter nulo
\\0, tienen que reportar esto como "String contains null character".
En cualquier caso, el análisis debería de continuar hasta el final del string. El final del string es definido tanto como:
- El principio de la siguiente línea si un newline es encontrado después de encontrar el error.
- Después de cerrar el string con
".
Otros errores que debe reportar:
- Si un comentario está abierto y se encuentra el caracter
EOF, se tiene que reportar este error con "EOF in comment". Por favor no tokenizen el contenido de los comentarios simplemente porque no se ha cerrado. De forma similiar en los strings, si unEOFes encontrado, reporten el error como "EOF in string constant". - Si miran un
*)fuera de un comentario, tienen que reportar el error como "Unmatched *)", en vez de tokenizar esta secuencia de caracteres como*y).
Recuerden, esta fase del compilador solo detecta una cantidad limitada de errores. No tomen en cuenta ni verifiquen errores que no son errores léxicos en esta fase. Por ejemplo, no deberían de verificar si las variables han sido declaradas anteriormente. Asegúrense de entender que errores la fase de análisis léxico puede considerar y cuales no antes de empezar.
3.2 Tabla de Strings¶
Los programas suelen tener muchas ocurrencias del mismo lexema. Por ejemplo, un identificador es generalmente referenciado múltiples veces dentro de un programa (de lo contrario no sería muy útil). Para ahorrarnos un poco de espacio y tiempo, una práctica común en compiladores es guardar los lexemas en una tabla de strings. Nosotros les proveemos una implementación en Java para esto. Vean las siguientes secciones para más detalles.
En fases siguientes tendremos que manejar los identificadores especiales como Object, Int, Bool, String, SELF_TYPE y self. En esta fase no debe hacer nada especial con ellos.
No verifiquen que las literales enteras caben dentro de la representación especificada en el manual de COOL. Simplemente creen un Symbol con el literal completo como el contenido del token, sin importar su tamaño.
3.3 Strings¶
Su analizador léxico deberia de convertir los caracteres que se les antepone un caracter de escape en las constantes string a sus valores correctos. Por ejemplo, si el programador escribe los siguientes ocho caracteres:
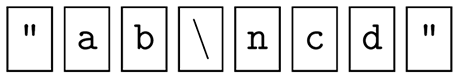
Su analizador léxico va a retornar un token STR_CONST cuyo valor semántico es estos 5 caracteres:

Donde \n representa el caracter de newline de la tabla ASCII. Siguiendo la especificación de la página 15 del manual de COOL, ustedes deberían de retornar un error para un string que contenga el caracter null. Sin embargo, la secuencia de estos dos caracteres:
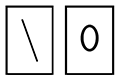
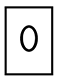
Debería de ser convertida a un caracter:
3.4 Otros detalles del lexer¶
Su analizador léxico debería de mantener una variable llamada curr_lineno, que indica que línea del archivo de entrada está siendo analizada. Esto va a ayudar al parser a imprimir mensajes de error útiles. Ignoren el token LET_STMT, es utilizado únicamente por el parser. Finalmente, noten que si la especificación léxica está incompleta (algunas entradas no tienen expresiones regulares que hagan match), entonces el lexer generado por JLex va a realizar cosas no deseables. Asegúrense de que su especificación esté completa.
4. Notas de Java¶
- Cada llamada al lexer retorna el siguiente token y lexema de la entrada. El valor retornado por el método
CoolLexer.next_tokenes un objeto de la clasejava_cup.runtime.Symbol. Este objeto tiene un campo que representa el tipo del token (por ejemplo si es un entero, punto y coma, dos puntos, etc). Los tipos de cada token están definidos en el archivo TokenConstants.java. El lexema (si el token tiene) también es colocado en el objetojava_cup.runtime.Symbol. La documentación para la clasejava_cup.runtime.Symbolestá disponible en las referencias. - Para los identificadores de clase, de objeto, enteros y strings, el lexema al final queda con el tipo
AbstractSymbol. Para las constantes booleanas, el lexema queda con el tipojava.lang.Boolean. Excepto para los errores (vean abajo), los lexemas para otros tokens no tienen ninguna información interesante. Dado que el campo value en la clasejava_cup.runtime.Symboles de tipo Object, ustedes van a necesitar castear este valor antes de utilizarlo en fases posteriores. - Nosotros les proveemos una implementación para esto, que esta definida en el archivo AbstractTable.java. Ustedes usaran las tablas
idtable,inttableystringtableque allí se encuentran. - Cuando un error léxico occura, la rutina
CoolLexer.next_tokendebería de retornar unjava_cup.runtime.Symbolcuyo tipo esTokenConstants.ERRORy cuyo lexema es el mensaje de error.
5. Probando su Lexer¶
Hay dos maneras en la que ustedes pueden probar su analizador léxico. La primer forma es generar archivos de entrada y correrlos utilizando su lexer, que imprime la línea y el lexema de cada token encontrado por su lexer. La otra forma, cuando piensen que su lexer esté funcionando correctamente, prueben correr ./mycoolc para correr su lexer junto con otras fases del compilador (que nosotros les proveemos).
6. Autograder¶
El autograder se subirá en el GES cuando veamos un avance significativo en sus proyectos. Deben hacer muchas pruebas de forma manual antes de empezar con el autograder.
Cuando estén listos para utilizarlo, primero deben darle permiso de ejecuciónÑ
chmod +x pa1-grading.pl
Cada vez que quieran ejecutar el autograder deberían de hacer lo siguiente:
./pa1-grading.pl
Referencias¶
- JFlex Manual - Manual de JLex.
- The Cool Reference Manual - Manual de COOL.
- Tour of the Cool Support Code - Manual del Código de Soporte de COOL.